KM Component 36 – Metadata and Tags

Stan Garfield
Metadata and tags are information about information – data fields added to documents, web sites, files, or lists that allow related items to be listed, searched for, navigated to, syndicated, and collected.
Metadata allows information to be found through browsing, searching, and other means. It defines the context of the information, how it is classified within a taxonomy, and how it is related to other information. Metadata may be applied automatically based on the origin of the content, assigned by the content owner when submitting it to a repository, or added by a knowledge manager or assistant to ensure it is done properly.
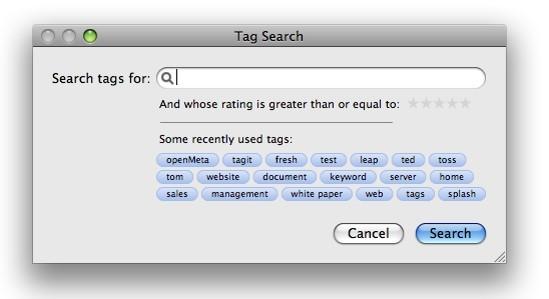
Tags are a form of metadata that can be applied by users to help them retrieve content according to their own view of how it should be categorized. Tags can be applied to web pages, documents, people, photos, music, and any other form of electronic content. These tags can also allow others to find content based on a folksonomy. The problem with a folksonomy as opposed to a taxonomy is that there are no imposed standards, and thus inconsistent tags will likely exist for information that should be tagged uniformly.
Metadata should be based on the standard taxonomy defined for the organization. It should be embedded in repository entry forms as mandatory fields with pick lists so that contributed content is correctly classified. Search engines should offer the option to search by the available metadata fields so that results will be as specific as possible.
Examples of metadata are customer name, industry, country, product or service, project identifier, technology type, date, revenue amount, etc. Whenever possible, metadata values should be supplied from a table, rather than entered as free-form text in an input field. The reason for this is that if, for example, each user is allowed to enter the customer name, then there will be many variations, and it will be difficult to search by customer name. If one user enters GM and another enters General Motors, the value of metadata is diminished. Offering a pick list containing the standard customer names will avoid this problem.
Metadata Example

Tagging Example
See also:
Stan Garfield
Please enjoy Stan’s additional blog posts offering advice and insights drawn from many years as a KM practitioner. You may also want to download a copy of his book, Proven Practices for Implementing a Knowledge Management Program, from Lucidea Press. And learn about Lucidea’s Inmagic Presto and SydneyEnterprise with KM capabilities to support successful knowledge curation and sharing.
Similar Posts

The KM Mentor, Part 3: Advice for an IT Professional at a Culinary Institute
KM expert Stan Garfield provides advice for a culinary institute IT staff member on how to develop training materials, prioritize KM initiatives, and support chef-instructors and students.

The KM Mentor, Part 2: Advice for a Music Festival Librarian
KM expert Stan Garfield advises a new music festival librarian on how to build a sustainable library and knowledge management program in one year.

The KM Mentor, Part 1: Advice for an Architecture Firm Librarian
How can a solo librarian at an architecture firm address knowledge gaps? Stan Garfield shares practical advice for developing an effective KM strategy.

The KM Cure, Part 3: Knowledge Rot
Stan Garfield explores how knowledge rot—outdated, inaccurate, conflicting, redundant, or missing information—causes costly errors and poor decisions without active curation.
Leave a Comment
Comments are reviewed and must adhere to our comments policy.
0 Comments