Only You Can Prevent Knowledge Loss: How to Practice “Knowledge Archaeology”

Stan Garfield
In this post, I address the different kinds of lost knowledge—content that was once available online, but no longer appears to be accessible.
I identify the causes and provide examples of each. I describe my approach to recovering lost knowledge, coining the term “Knowledge Archaeology.” In addition, I describe ways to keep valuable knowledge accessible.
David DeLong wrote the book Lost Knowledge specifically about the threat of an aging workforce, which is one important example of knowledge loss. I included an infographic about how to deal with this challenge in my last book for Lucidea:
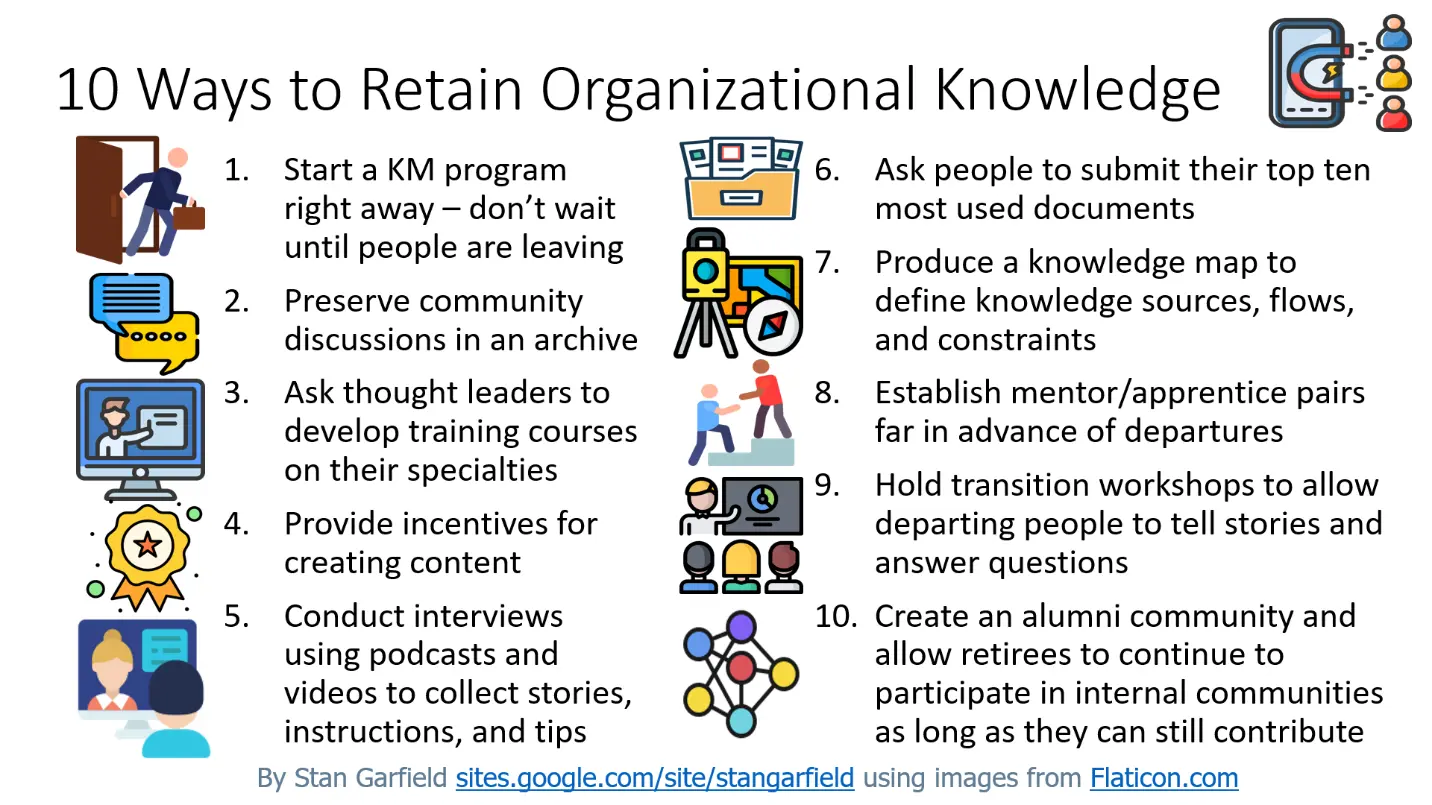
In my latest book for Lucidea, Profiles in Knowledge: 120 Thought Leaders in Knowledge Management, I curated content from each of the featured 60 women and 60 men. Each profile originally appeared as a separate blog post, which I periodically review to check for links that no longer work. In doing so, I repeatedly encounter broken links to articles, presentations, and blog posts. Unfortunately, every year when I return to an old post, more links are broken.
What Causes Knowledge Loss?
Content becomes unavailable through multiple causes. These include:
- Retirement: A blogger retires and removes their content and/or their site.
- Departure: A content provider leaves an organization, and their content is removed from the organization’s site.
- Illness or death: An author, or their partner, becomes sick or dies, and as a result, a required payment for their site or blog platform is missed. This results in the deletion of their content by the site owner.
- Defunct platform: The provider of a site that hosted content goes out of business or ends the service, and the platform disappears, with or without warning.
- Content removed: The content owner or site owner removes content.
- Site repurposed: The focus of a site changes, either due to a change of focus by the content provider or due to a takeover of the site by a different owner.
- Site reorganized: The owner of a site decides to restructure or rename it, leading to a change in all URLs of the content on the site. No redirection of the old URLs to the new ones is provided.
- Hacking: A hostile takeover, either for ransom or malicious intent, results in the content being deleted, altered, or no longer accessible.
- Content corrupted: An article or blog post, while still accessible, is garbled or altered so that it is either useless or compromised. This is due to changes in the software that runs the platform, and while not with hostile intent, diminishes or eliminates the original content.
- Paywall: Content that was once freely available is placed behind a paywall and is only available to those who are willing to pay.
How Knowledge is Lost: Real-World Examples
Retirement
When Verna Allee retired, she removed all of her online content, including the entire vernaallee.com site. I was able to retrieve her content using the Wayback Machine.
Departure
When I left HP in 2008, my blog posts on hp.com remained for some time. However, they were eventually removed. Using my original files, I updated and republished them to my blog site on Medium. Most of the original versions are also available in the Wayback Machine.
Illness
In a Facebook post in September 2024, long-time blogger Lilia Efimova wrote:
“My blog, which used to be my professional presence online for many years, is lost.
At some point (my husband) took care of its hosting, together with all other family and business stuff. Backups were done online, at the hosting website. The remainder of hosting payments went unnoticed in his email for months (due to illness) and by the time I found out that my blog stopped working, the data was deleted without any chance to restore.”
Most of her blog posts are available in the Wayback Machine. However, for some posts for which the Wayback Machine made no snapshot, the content is lost forever.
Defunct platforms
I posted content from my first two years of blogging to Line56.com and hp.com Communities, neither of which still exists. I had to restore all of my blog posts from these two platforms.
My personal website is on Google Sites. It started on Google Pages and was automatically migrated to the original version of Google Sites. I was forced to migrate it later to a new version of Google Sites, which was partially automated, but still required a lot of manual effort.
I used to post on Google+. When that platform shut down, all my content was lost.
Seeking alternatives to Twitter, I started using Post.news. It offered an automatic replication feature from Substack that I took advantage of, but not long after I started using it, the platform closed.
The SIKM Leaders Community started on Yahoo! Groups. When Yahoo! announced the end of life of the platform, I was able to migrate all existing content to Groups.io. Much of this was automated, but I had to manually insert updated links to files, attachments, and monthly call summaries. There was no such luck with the repository of recordings of the community’s monthly call on divShare. It suddenly disappeared without warning, and all recordings were lost. Some original copies had been kept and were made available again on Microsoft OneDrive, but not all.
Content removed
Euan Semple changed his personal site, and for a long time, his older blog posts were unavailable. He recently restored them to his new site, but unfortunately none of the original URLs work.
Site repurposed
Graham Durant-Law changed his site’s focus from knowledge management to bagpiping. All of his KM content was removed, but I was able to retrieve it from the Wayback Machine.
When the KM4Dev Community migrated its online discussions from dgroups.org to dgroups.io, the original site was taken over and renamed to KMTools. It was viewed as a hostile action.
Site reorganized
Matt Moore made a subtle change to the URL of his blog, removing the final “s” in EngineersWithoutFears to result in the new URL, EngineersWithoutFear. No content was lost, but there was no redirection of the old URL to the new one.
Dave Snowden’s company site was renamed from Cognitive-Edge.com to TheCynefin.co. All URLs were successfully redirected to prevent any disruption in access to the important content.
Hacking
The ActKM Community was once a thriving KM community hosted in Australia but valued and participated in across the world. Hackers stole the domain and shut down the site, and all of the many valuable threaded discussions were lost.
Content corrupted
On several occasions, when editing an old LinkedIn article to update its content, I encounter totally unformatted text, with all links and images missing. Fortunately, I maintain a second copy of each article on Medium, so I am able to quickly recover. Without the backup, I would have to spend a great deal of time recreating the original version.
Paywalls
SlideShare, once owned by LinkedIn (which in turn, was owned by Microsoft), was sold to Scribd. They added annoying ads and required paid membership to download presentations. For sharing the presentations of the monthly SIKM Leaders Community calls, I switched to Microsoft OneDrive.
How to Locate Missing Information Online
When I encounter a broken link, or when I am searching for content that was available in the past but is no longer accessible, I use an approach I call “Knowledge Archaeology.” This is a regular and important part of my writing. Here is how I do it.
- Search on Google. Enter the exact title of the content you are seeking. Look for copies of the content made by others. If none are found, look for pointers to the content you are seeking that have old links that no longer work. Then use those links in step 2.
- Plug URLs into the Wayback Machine. Use the last-known URL of the content or one found in step 1. If the Wayback Machine has one or more snapshots of that URL, it will display all the years in which the snapshots were taken. Choose a year that shows a vertical bar, and then look for the dates with blue circles and click on the time of a snapshot. You may need to review multiple snapshots from different years in order to find specific ones that contain the actual missing content.
- Follow the trail. If there is no snapshot of the exact URL in the Wayback Machine, try using just the first part of the URL, and asking the Wayback Machine to show all snapshots using that first part. Look for landing pages, a table of contents, or a blog calendar and look for links from there. Try different dates, zeroing in on when the page you are seeking first appeared.
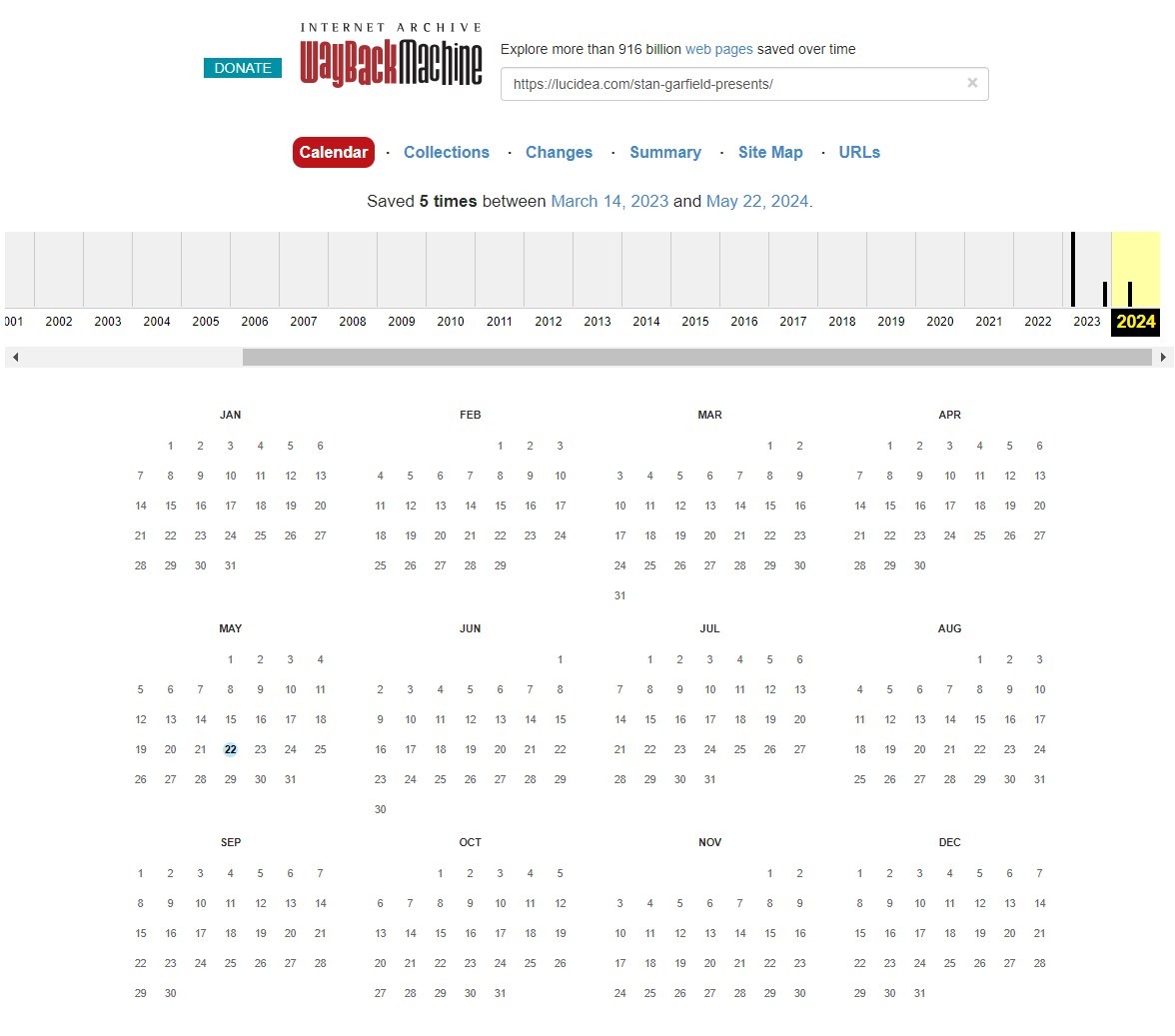
How to Keep Content Accessible
If you blog or provide other content for public consumption, here are tips to ensure that your content remains available to your readers.
- Use platforms that are likely to persist. Nothing is forever, but Google, LinkedIn, and Microsoft are likely to be around for a while.
- Keep your own copy of all published content. Save it into a document, and store that document in a cloud service such as Microsoft OneDrive where it will be accessible and regularly backed up.
- Post to at least two public platforms. On social media, I post twice: once on Twitter and once on LinkedIn. For blogs, I post a copy on Medium of each LinkedIn article, Lucidea post, and Quora answer.
- Don’t remove content. Just because it’s old doesn’t mean that it isn’t useful. On my Google Site, I maintain copies of everything I have written. I still refer to many of my old blog posts, articles, and presentations, and I know that others do as well.
- Don’t change URLs. If you must, then add redirects from the original URLs.
- Don’t require a login. I provide read access to all SIKM Leaders Community threaded discussions, unlike KM4Dev, which requires members to login to read discussions.
- Post on a site that you control: In Post on your own site, Harold Jarche wrote, “social media channels (controlled by someone else) come and go.”
- Use tools that provide access to all previous versions of content. In case you, or someone else with access, inadvertently deletes or alters content and you want or need to revert to a prior version, you will be able to do so. A wiki is an example of such a tool.
- Have co-owners for your site. If something happens to you, someone else will be able to continue managing your site.
- Use strong passwords. Don’t make it easy for hackers to disrupt or take control of your site.
Automatic Archiving: Best Practice or Not?
For internal content within an enterprise, here is an additional piece of advice: don’t automatically archive content.
Knowledge repositories often are configured to automatically archive documents after some predetermined period of time. The intent is that after content has been available for 90 days (or whatever duration is chosen) it is no longer current, and thus should be removed from the repository. The assumption is that this old content should not appear in search results or in lists of available documents. Reasons for this include:
- Old documents are no longer relevant, accurate, or useful.
- Searches yield too many results, so weeding out old documents will improve user satisfaction with search.
- Content contributors should refresh documents periodically.
Contributed content does not automatically become obsolete after a fixed period of time. It may remain valuable indefinitely. I offer the analogy that just because Peter Drucker died in 2005, we don’t remove his books from the library. His insights will continue to be useful for a very long time.
One firm where I worked had an automatic archiving process. As a result, I would often receive messages from frustrated users who were searching for content that they had previously found in the repository but could no longer find. I would have to restore this content from the archive to the active repository. This caused users to be annoyed with the KM program, resulted in a lot of wasted time and effort, and sometimes delayed the retrieval of important information needed for client work.
With the cost of mass storage steadily decreasing, there are few good reasons to remove content from knowledge repositories unless it is known to be outdated, incorrect, or useless. Instead, ensure that the search engine can limit results by the date of the knowledge object. Defaults can be set to limit results to the last 90 days, one year, or whatever duration is desired. It should be easy for users to change the date range to include older content in the search results.
If this is not possible, then you will need to actively curate internal content that has been archived due to automatic archiving processes but is still in demand. To do so, retrieve it from the archives, restore it to internal repositories, and modify the expiration date so that it will not be archived again.
Using Knowledge Archaeology to Prevent Knowledge Loss
There is no end to the continuing loss of resources that used to be available and would still be useful. To address this, I use “knowledge archaeology” to find and restore the missing content. I hope the techniques outlined here will be useful to you in your own pursuit of knowledge.

Searching for KM software that enables you to curate, manage, and share organizational intelligence in a single venue? Get in touch to learn about Presto!
Stan Garfield
Please enjoy Stan’s blog posts offering advice and insights drawn from many years as a KM practitioner. You may also want to download a free copy of latest book, Profiles in Knowledge: 120 Thought Leaders in Knowledge Management, from Lucidea Press. Learn about Lucidea’s Presto, SydneyDigital, and GeniePlus software with unrivaled KM capabilities that enable successful knowledge curation and sharing.
**Disclaimer: Any in-line promotional text does not imply Lucidea product endorsement by the author of this post.
Never miss another post. Subscribe today!
Similar Posts

The KM Mentor, Part 3: Advice for an IT Professional at a Culinary Institute
KM expert Stan Garfield provides advice for a culinary institute IT staff member on how to develop training materials, prioritize KM initiatives, and support chef-instructors and students.

The KM Mentor, Part 2: Advice for a Music Festival Librarian
KM expert Stan Garfield advises a new music festival librarian on how to build a sustainable library and knowledge management program in one year.

The KM Mentor, Part 1: Advice for an Architecture Firm Librarian
How can a solo librarian at an architecture firm address knowledge gaps? Stan Garfield shares practical advice for developing an effective KM strategy.

The KM Cure, Part 3: Knowledge Rot
Stan Garfield explores how knowledge rot—outdated, inaccurate, conflicting, redundant, or missing information—causes costly errors and poor decisions without active curation.
Leave a Comment
Comments are reviewed and must adhere to our comments policy.
0 Comments